Сервисы конкурентного мониторинга позволяют вам точно знать, как развивается сайт.
Полученные данные помогают конкурентам превзойти конкурентов в результатах поиска.
Как скрыть ценную информацию от конкурентов? Мы проанализируем наиболее эффективный метод, после которого конкуренты больше не смогут анализировать ваш сайт.
Содержание
1 — Постановка целей: зачем запрещать роботам доступ к сайту?
Службы конкурентной разведки позволяют загружать ценную информацию на ваш сайт. Полезная информация включает в себя: структуру сайта, внешние ссылки, текстовый контент и т. д.
Большинство предложений на рынке услуг по продвижению основано на копировании стратегий поисковых лидеров.
Работа включает в себя простые шаги:
- Изучите конкурентов. Например, с помощью службы исследования конкурентов MegaIndex;
- Скачивайте ценные данные с сайтов-конкурентов;
- Копирование решений.
Рекомендуемый материал в блоге MegaIndex по ссылке — Поиск конкурентов по ключевым словам. Бесплатно. Как найти и почему.
Ценные данные включают в себя:
- Внешние ссылки из частной сети сайтов;
- Структура сайта;
- Контент в виде заголовков, h1-h6, фрагментов и содержимого главной страницы.
Данные о внешних ссылках можно найти с помощью службы внешних ссылок MegaIndex.
Копирование успешных стратегий — действительно эффективное решение.
Существуют разные способы скрыть свой сайт от служб конкурентной разведки.
Наименее эффективный — это запрет в файле robots.txt.
Директива robots.txt является рекомендацией и не правило. Авторитетные сервисы, такие как MegaIndex, учитывают рекомендации. Но файл robots.txt не является гарантией от сканирования сайта другими сервисами.
Действенный способ — бан на уровне сервера. Пример кода размещен по ссылке — запретить анализ сайта на уровне сервера.
Идея правильная, но метод не идеален.
2 — Проблема: Как боты сканируют сайты в обход банов?
При обращении к сайту на сервер отправляется запрос, содержащий информацию о клиенте. Звонки записываются в журнал посещений, так называемый файл называется газеты. В лог-файле хранится информация обо всех обращениях к сайту.
Каждая строка содержит Пользовательский агента также интеллектуальная собственность.
Поисковые системы представлены следующим образом:
- Googlebot;
- Яндекс*. Например, Яндексбот, ЯндексКалендарь, ЯндексМобильныйБот.
Услуги представлены таким же образом, например. МегаИндексБот.
Скрипт блокировки на уровне сервера отклоняет запросы на основе списка значений. Пользовательский агент.
Робот системы конкурентной разведки заблокирован. Но обойти защиту несложно. Например, представьте себя роботом вроде Яндексбота или Гуглбота. Некоторые сервисы публично заявили, что начали сканировать сайты под вымышленными именами.
Что делать? Я предлагаю решение, гарантирующее, что сайт не будет анализироваться службами конкурентной разведки. Дополнительный эффект – экономия трафика.
Принцип заключается в проверке точности робота.
3 — Решения. Как предотвратить анализ веб-сайта системами конкурентной разведки
Метод основан на использовании строки запроса для сервер доменных имен.
Процедура следующая.
Шаг 1. Робот поисковой системы заходит на сайт. Указывается в строке запроса. Пользовательский агент для поисковых систем Google и Яндекс. Загрузка IP-адреса.
2-й шаг. Определяем хост по IP-адресу; Для этого выполняем обратный DNS-запрос.
Проверяем, принадлежит ли хост Яндексу или Google. Все хосты Googlebot заканчиваются на googlebot.com или google.com. Хосты всех роботов Яндекса заканчиваются на yandex.ru, yandex.net или yandex.com. Если имя хоста имеет другое окончание, то робот не принадлежит поисковой системе.

Шаг 3. Выполняем прямой DNS-запрос для переадресации хоста на IP, для этого выполняем прямой DNS-запрос. Мы получаем IP-адрес, соответствующий имени хоста.
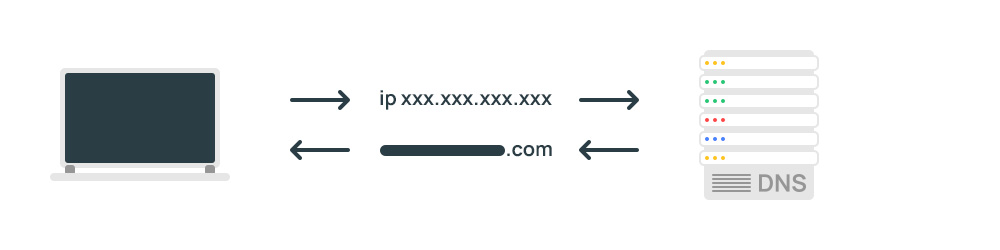
Шаг 4. Адрес должен совпадать с IP-адресом, используемым при обратном поиске DNS. Если IP-адреса не совпадают, полученное имя хоста будет ложным.
В результате запросы, отправленные на сайт конкурентными разведками, были заблокированы. Доступ к сайту открыт роботу поисковой системы.
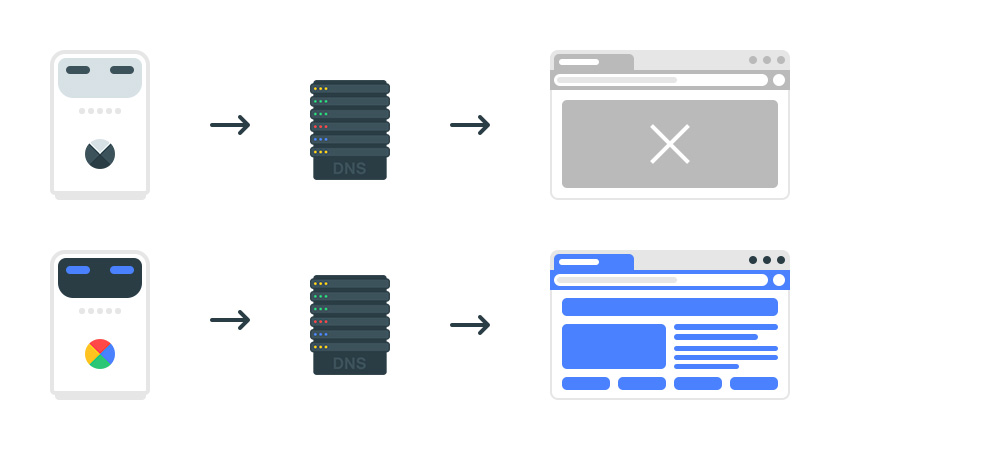
Как выполнить обратный поиск DNS?
Для реализации блокировки необходим скрипт, выполняющий описанную процедуру. Методика реализована на любом популярном языке.
Чтобы понять процесс, я покажу вам, как проверить это самостоятельно.
Например, через консоль Windows проверка осуществляется с помощью следующих команд:
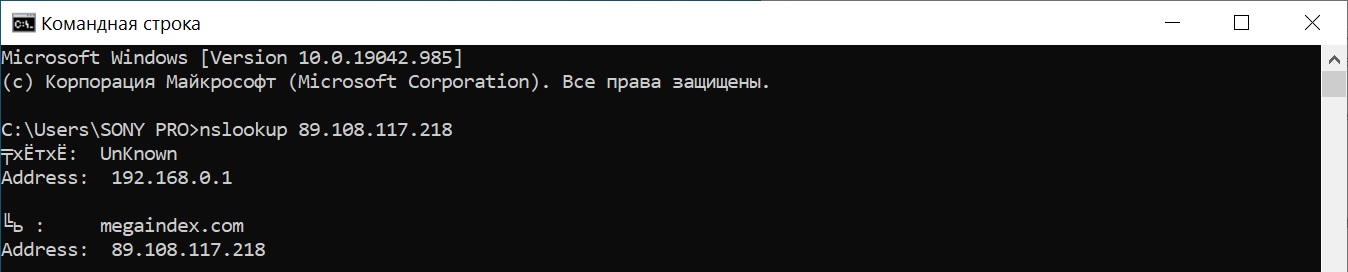
Запрос с помощью команды nslookup:
nslookup 89.108.117.218
Результат:
Запросить с помощью пингер:
ping -a 89.108.117.218
выводы
Часто системы конкурентной разведки и спамеры заходят на сайт под видом поисковых ботов.
Системы конкурентной разведки позволяют выявить ценные разработки в продвижении веб-сайтов.
Данные о проделанной работе по поисковой оптимизации позволяют конкурентам повторить успех.
Рабочий процесс довольно прост:
Повторить стратегию поискового лидера легко, поэтому следует закрыть сайт от систем анализа.
Есть несколько распространенных простых методов. Например:
- Используйте бан на уровне сервера. Пример кода опубликован на индексоид;
- Отказаться через роботов.
Проблемы следующие:
- Директивы роботов выполняются не всеми роботами;
- Бан на уровне сервера позволяет получить принудительную блокировку. Но есть способ обойти защиту. Как? Блокировка осуществляется на основе User-Agent. Решением обхода блокировки является фальсификация передаваемого значения.
Поисковые системы, в том числе Google и Яндекс, не публикуют списки адресов поисковых ботов.
Как ты можешь быть уверен, что Это робот поисковой системы, который сканирует сайт?
Для проверки нужно запустить Обратный DNS запрос.
Если Прямой DNS запрос получает IP-адрес хоста, затем обратный DNS-запрос получает хост по IP-адресу.
Система проверки с использованием DNS позволяет заблокировать как основной сайт, так и сайты-сателлиты от сканирования любым внешним сервисом.
Алгоритм проверки включает в себя следующие этапы:
- Если к сайту обращается Googlebot, Яндекс*, загрузить данные IP;
- Выполните обратный DNS-запрос. Убедитесь, что результатом является доменное имя, принадлежащее поисковой системе. Для Яндекса — yandex.ru, yandex.net или yandex.com. Для Google — googlebot.com или google.com;
- Выполните прямой DNS-запрос, чтобы преобразовать хост в числовой адрес.
- Проверьте соответствие. IP-адрес должен совпадать с IP-адресом, используемым при обратном поиске DNS. Если IP-адреса не совпадают, это означает, что сайт сканируется не поисковой системой, а поддельным хостом.
Результат:
- Сайт доступен для определенных роботов поисковых систем;
- Сайт доступен пользователям;
- Все страницы сайта закрыты для разведывательных систем.

Поэтому сервер не передает контент сторонним сервисам. Алгоритм позволяет экономить трафик и защищать сайт от сторонних ботов.
Существует множество настроек DNS. Если вы хотите узнать больше об оптимизации сайтов с помощью DNS, пишите в комментариях.
Еще есть вопросы? Есть ли что добавить к материалу? Хотите знать, как отличить робота от пользователя? Напишите сообщение в комментариях.




